
Coze 复刻吴恩达开源 AI 翻译神器 | 「智图派」


AI 最大的应用场景之一,就是翻译。虽然说现在的 AI 翻译比以前的机器翻译好了很多,但是常常还是不够完美。不过现在呢,有一种超强的方法可以显著提升 AI 翻译的水准,这就是 AI 界大神,吴恩达 Andrew Ng 教授最新开源的「反思工作流」
它利用prompt engineering,让AI不仅能翻译,还能"思考"如何改进翻译!这意味着,无论你要翻译的文档有多专业、多复杂,都能得到一个高度定制化的优质翻译。我们可以先看一下翻译效果。
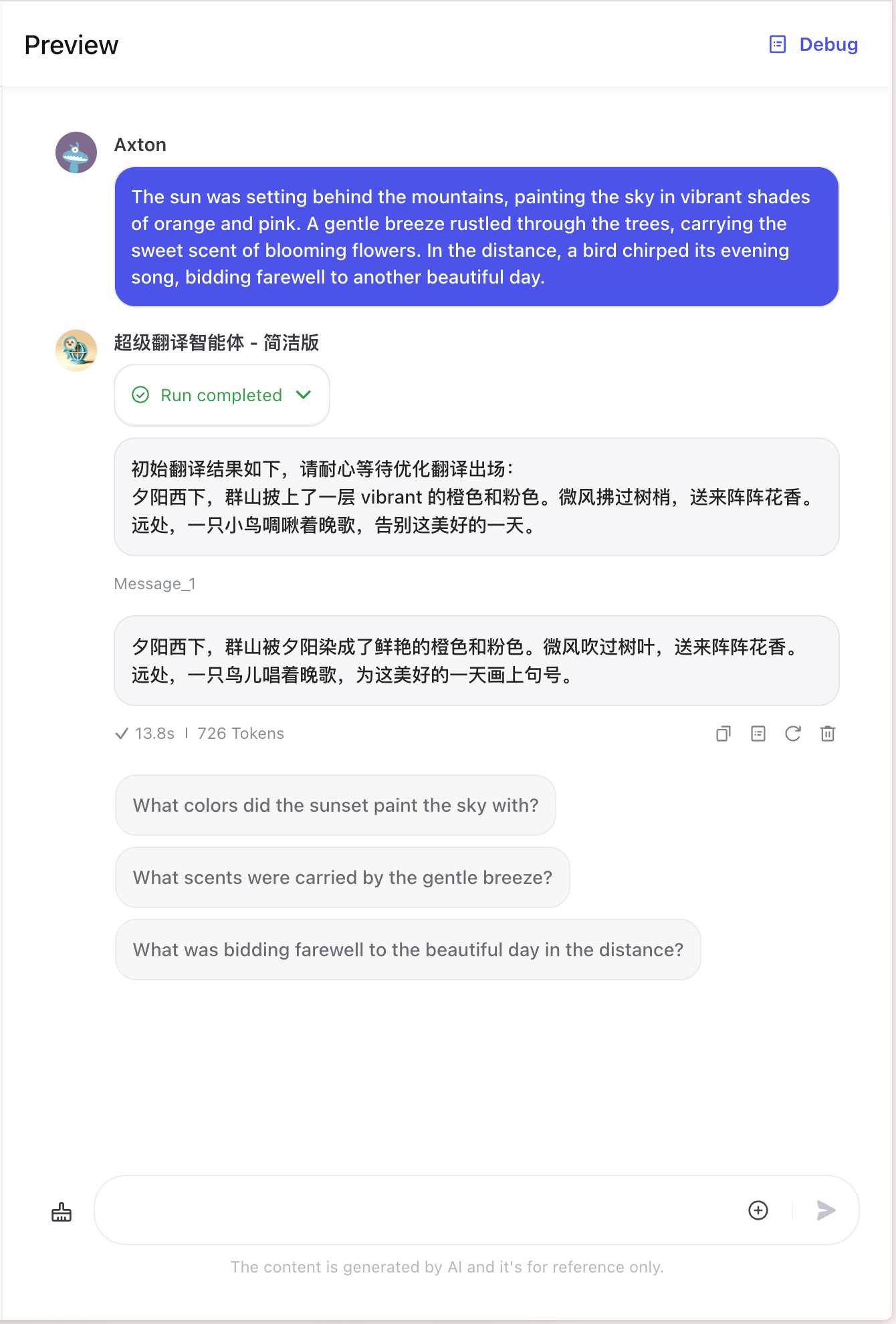
吴恩达老师的反思翻译核心思路
吴恩达老师的翻译工作流可以归纳为两个核心要点:
第一,采用"初始翻译-反思-优化"的三步迭代流程,不断改进翻译质量。首先使用一个 AI 进行初始的翻译,然后让另一个 AI 对初始的翻译结果进行思考和评判,找出可以改进的地方,最后,由第三个 AI 根据反思结果,对初始翻译进行优化输出最终的翻译结果。
第二,引入分块和特定国家地区语言习惯指定,进一步提升翻译的细节品质。把很长的文章进行分块,一方面可以突破 AI 输出文本长度的限制,另一方面 AI 聚焦在一小段文本上的优化会有更高的精度。同时,为AI指定目标语言的国别(如英式英语、美式英语)和语言习惯,翻译会更贴合目标读者的文化背景。如果再加上语气以及术语表,将会使翻译结果更加精准。
总的来说,吴恩达老师的翻译工作流通过"反思"实现翻译的整体质量提升,通过"分块"和"习惯指定"实现翻译细节的精准优化。这两大创新点共同开创了一种全新的、高质量的AI翻译范式。
Coze AI 工作流简介
由于开源的项目是纯代码,用起来并不方便,因此我在 Coze 平台上完美复刻了吴恩达老师的反思翻译工作流。今天我将手把手教你如何在 Coze 平台上从零实现一个「反思型」AI 翻译的自动化工作流。跟着我一步步操作,你也能拥有一个强大的AI翻译助手!当然,你如果懒得动手,也可以直接在 Coze 的聊天机器人商店中搜索我的「超级翻译智能体」,一个是简洁版、一个是强力版,可以直接使用。这两个版本的区别就是,强力版可以对长文进行分块。
Coze 是一站式 AI Bot 开发平台。无论你是否有编程基础,都可以在 Coze 平台上快速搭建基于 AI 模型的各类问答 Bot,还可以发布到各类社交媒体,与大家互动。我们最初认识 Coze,就是它慷慨地提供了免费使用 GPT-4 Turbo 的额度,在我的 Coze 入门视频中有讲到。而它更强大的地方,在于我们可以制作复杂的工作流。
我们的「超级翻译智能体」的工作流,就用到了 Coze 工作流中各种高端特性,比如条件分支、代码块、批处理等等,我们先看一下整体的工作流以及运行效果。
超级翻译智能体工作流
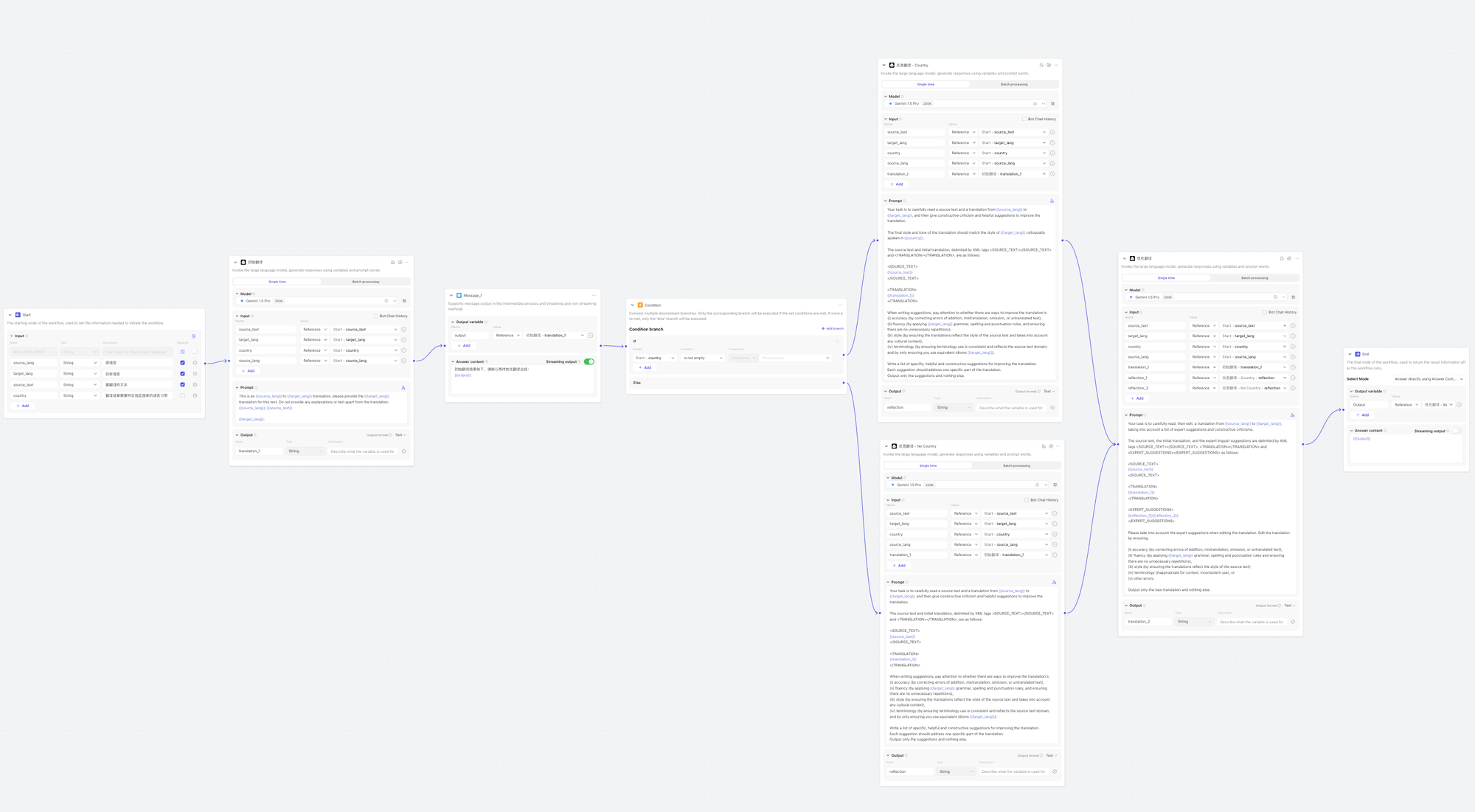
这部分是吴恩达老师的反思翻译工作流的核心流程,也是用于我们的简洁版的「超级翻译智能体」的工作流,所以起名为 Super_Translation_Core,Core 就代表核心的意思。而具备分块功能的工作流,就是建立在这个核心工作流的基础之上。
工作流的输入参数
工作流接受 4 个输入参数,分别是源语言、目标语言、要翻译的文本以及最终的翻译结果应该符合哪个国家地区的语言习惯。
接下来的部分就是几个关键的翻译节点了。
工作流节点
初始翻译
首先是初始翻译的节点,这是一个 LLM 节点,也就是大语言模型节点。我们可以选择任何一个模型,比如 GPT 或者 Gemini,由于 Coze 对使用模型的额度是有一定限制的,因此当一个模型用超了之后,可以换一个模型继续使用。
PROMPT 很简单,就是要求 AI 把提供的文本翻译成目标语言,不要进行任何的解释,纯粹翻译就行,然后输出翻译后的文本。
This is an {{source_lang}} to {{target_lang}} translation, please provide the {{target_lang}} translation for this text. Do not provide any explanations or text apart from the translation.
{{source_lang}}: {{source_text}}
{{target_lang}}:
消息节点
消息节点用于在工作流的执行过程中,向用户输出信息。由于我们的翻译工作流用到了三次 AI 翻译,因此速度必然会很慢,用户等起来容易丧失耐心,所以我们可以在初始翻译完成之后,把初始翻译的结果输出给用户,让用户知道工作流还在工作呢。当然,这一步是可选的。没有这一步也并不影响工作流的功能。
条件节点
工作流的输入参数中,有一项是参数是国家和地区,用于告诉 AI,翻译结果应该符合哪个地区的语言习惯,这一个参数是可选参数,大部分情况下是不需要的。而且,有没有这个参数,给 AI 的 PROMPT,提示词,也会不一样,所以我们在这一步要进行一次条件判断,因此加入一个 Condition 条件节点。
判断条件很简单,就是看开始节点的 Country 参数,有没有内容。如果有,就说明提供了国家地区的参数。因此我们判断的条件就是这个参数是否为空。
反思翻译
条件节点之后,就进入到了「反思翻译」阶段,这同样是一个 LLM 语言模型节点。它的 PROMPT 就有些复杂了,主要的目的就是把所有参数提供的信息以及初始翻译后的文本,全部交给这个模型,要求它根据一定的评估条件,对翻译的结果进行评价并提出改进建议。
PROMPT 比较长,下面我们就把有 Country 这个参数的 PROMPT 翻译成中文供大家参考:
您的任务是仔细阅读一篇源文本和从{{source_lang}}翻译成{{target_lang}}的译文,然后提出建设性批评和有益建议以改进翻译。
最终翻译的风格和语调应与{{country}}口语中使用的{{target_lang}}风格相匹配。
源文本和初始翻译,由XML标记<SOURCE_TEXT></SOURCE_TEXT> 和 <TRANSLATION></TRANSLATION> 分隔如下:
<SOURCE_TEXT>
{{source_text}}
</SOURCE_TEXT>
<TRANSLATION>
{{translation_1}}
</TRANSLATION>
在撰写建议时,请注意是否有改进翻译准确性(通过纠正添加错误、误译、遗漏或未翻译文本)、流畅性(通过应用 {{target_lang}} 语法、拼写和标点规则,并确保没有不必要的重复)、风格(通过确保翻译反映源文本风格并考虑任何文化背景)、术语(通过确保术语使用一致且反映源文本领域;并只确保您使用等效习语 {{target_lang}})方面是否有改进空间。
列出具体、有帮助且富有建设性的改进建议清单。
每个建议都应针对一个特定部分进行。
原英文 PROMPT 如下:
Your task is to carefully read a source text and a translation from {{source_lang}} to {{target_lang}}, and then give constructive criticism and helpful suggestions to improve the translation.
The final style and tone of the translation should match the style of {{target_lang}} colloquially spoken in {{country}}.
The source text and initial translation, delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT> and <TRANSLATION></TRANSLATION>, are as follows:
<SOURCE_TEXT>
{{source_text}}
</SOURCE_TEXT>
<TRANSLATION>
{{translation_1}}
</TRANSLATION>
When writing suggestions, pay attention to whether there are ways to improve the translation's:
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),
(ii) fluency (by applying {{target_lang}} grammar, spelling and punctuation rules, and ensuring there are no unnecessary repetitions),
(iii) style (by ensuring the translations reflect the style of the source text and takes into account any cultural context),
(iv) terminology (by ensuring terminology use is consistent and reflects the source text domain; and by only ensuring you use equivalent idioms {{target_lang}}).
Write a list of specific, helpful and constructive suggestions for improving the translation.
Each suggestion should address one specific part of the translation.
Output only the suggestions and nothing else.
优化翻译
这是第三个翻译节点,同样也是 LLM 语言模型节点。它的任务是根据「反思翻译」节点的建议,对「初始翻译」进行优化,输出最终的翻译文本。
这部分的PROMPT与「反思翻译」部分大同小异,区别在于,给它的任务是:您的任务是仔细阅读并根据专家建议和建设性批评意见对翻译进行编辑。
Your task is to carefully read, then edit, a translation from {{source_lang}} to {{target_lang}}, taking into account a list of expert suggestions and constructive criticisms.
The source text, the initial translation, and the expert linguist suggestions are delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT>, <TRANSLATION></TRANSLATION> and <EXPERT_SUGGESTIONS></EXPERT_SUGGESTIONS> as follows:
<SOURCE_TEXT>
{{source_text}}
</SOURCE_TEXT>
<TRANSLATION>
{{translation_1}}
</TRANSLATION>
<EXPERT_SUGGESTIONS>
{{reflection_1}}{{reflection_2}}
</EXPERT_SUGGESTIONS>
Please take into account the expert suggestions when editing the translation. Edit the translation by ensuring:
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),
(ii) fluency (by applying {{target_lang}} grammar, spelling and punctuation rules and ensuring there are no unnecessary repetitions),
(iii) style (by ensuring the translations reflect the style of the source text)
(iv) terminology (inappropriate for context, inconsistent use), or
(v) other errors.
Output only the new translation and nothing else.
另外,把「反思翻译」节点给出的建议放到了专家建议的标签当中:
<EXPERT_SUGGESTIONS>
{{reflection_1}}{{reflection_2}}
</EXPERT_SUGGESTIONS>
这里面的建议使用了两个变量,reflection_1 和 reflection_2,分别是前两个「反思翻译」节点的输出结果。一个是指定了国家和地区的反思翻译,另外一个是没有指定的。由于前两个节点会根据「条件节点」的结果不同而执行不同的节点,不会两个节点都执行,所以把他们两个的输出结果全部写在一起是没有问题的,在一次执行过程中,只会有一个输出结果有内容,所以不会产生冲突和重复。
最后,把「优化翻译」最终生成的翻译内容作为输出,给到最后一个「结束」节点,整个工作流就完成了。我们点击「测试运行」来看一下效果。
测试成功之后就可以发布了,而发布之后,我们就可以把它集成在聊天机器人中让大家使用了。
超级翻译智能体 - Bot
工作流完成之后,我们就可以创建一个聊天机器人来使用这个工作流了,创建聊天机器人很简单,点击「Create Bot」,就可以创建一个机器人
聊天机器人的模型建议选择 GPT-4o,然后在 Skills,也就是技能树这边,只添加一项,就是我们刚刚发布好的工作流,Super Translation Core.
重点就是提示,把提示写清楚,我们把已经写好的 PROMPT 粘贴过来就可以了,这里要求它必须调用工作流来执行任务,否则 GPT 会自作主张帮你翻译,也就失去了我们使用「反思」翻译流程的意义了。
PROMPT 说明
详细 PROMPT 如下: