
一次处理 80 万汉字,Gemini 1.5 Pro 值得期待吗 「智图派」


虽然 OpenAI 的 Sora 火遍全网,吸引了大家的眼球,但是不要忽略了,Gemini 1.5 的突破性进展带来的深远影响。这甚至比 Sora 都更有意义。
Gemini 1.5 相比 Gemini 1.0,虽然只是半个版本号的变化,增加了 0.5,但是在性能方面具有很大的改进,以至于达到了 1.0 Ultra 版本的能力,但是消耗的算力却更少。
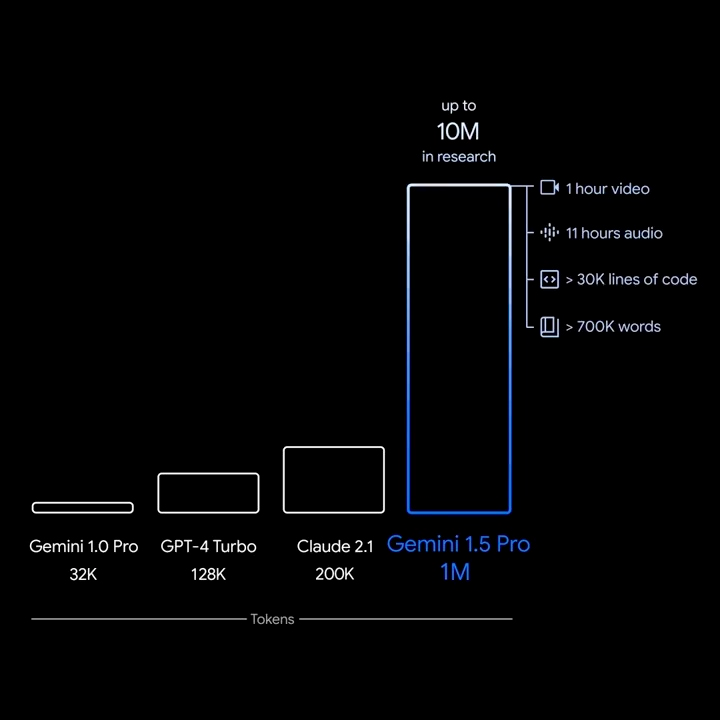
我们知道,Gemini 分为三个版本,其中 Pro 是中档版本,而 Ultra 是高级版。1.0 Ultra 是与 GPT-4 对标的,因此可以说,Gemini 1.5 Pro 版本已经达到了 GPT-4 的级别,而且在一项参数上,直接超越了 GPT-4 将近 8 倍甚至 80 倍,这就是 Token 数量。
Gemini 1.5 的 Token 数量达到了 100 万,如果不了解 Token 我们可以简单理解为 AI 能够处理的字数,一般一个汉字大约占 1.2 个 Token,所以 100 万 Token 相当于 Gemini 一次性处理一部 78 万 8 千字的「红楼梦」还绰绰有余。
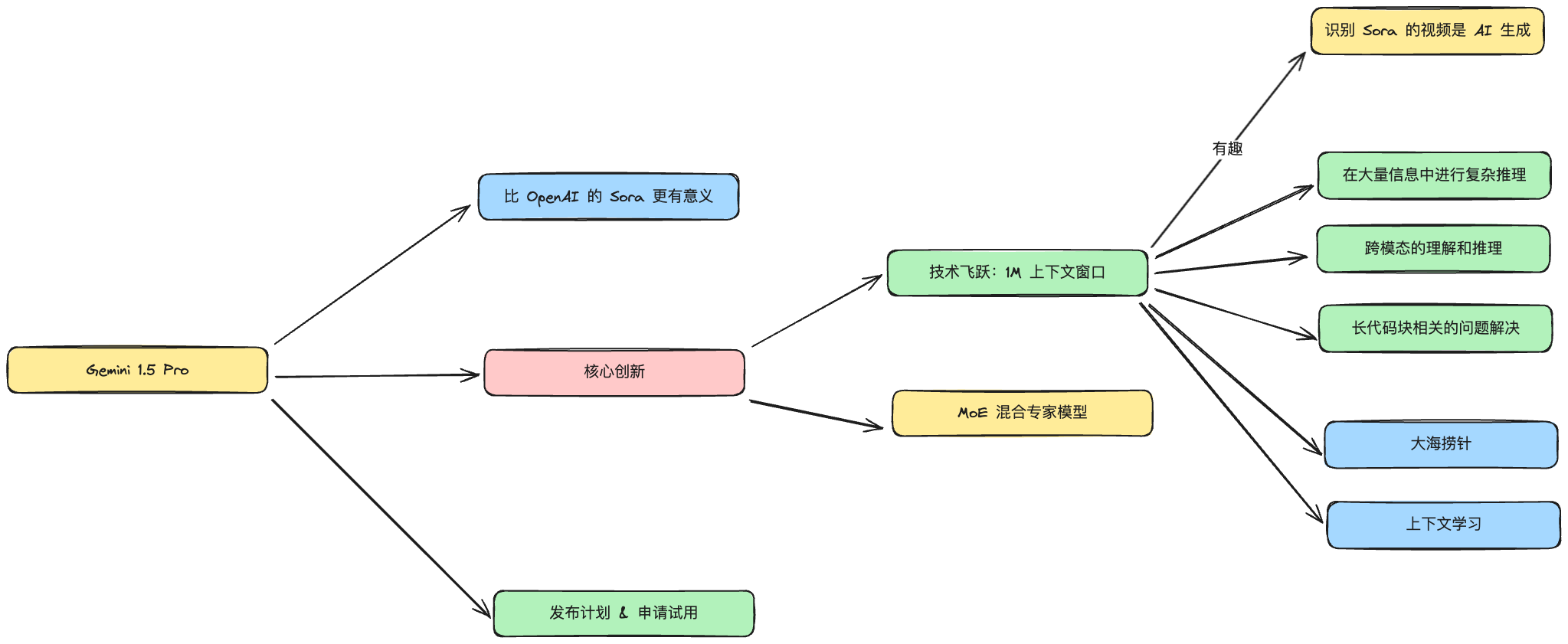
100 万 Token 就是 Gemini 1.5 的核心创新之一,另外还有一项是 Gemini 1.5 的技术架构是优化后的多模态稀疏混合专家模型。
把上下文窗口增加到 1M 而不牺牲性能,这是一项巨大的技术飞跃
我们先来简单对比一下就知道技术的发展有多快。一年以前,正是 ChatGPT 3.5 大火的时候,它的 Token 数量是 4 千,现在,GPT-4 的 最大 Token 是 12 万 8 ,Claude 是 20 万,而 Gemini 1.5 上来就把 Token 的天花板直接拔高了 5 倍,这还不算,Gemini 在实验中达到过 1000 万的 Token 数量。
那么,有这么大的数量,到底有什么意义呢?我们首先来看几个的例子。
大量信息中的推理能力。
首先是在一整本教科书中回答问题
这位叫做 Mckay 的推友把一本完整的生物学教科书输入到 Gemini1.5 Pro 中。一共491,002个 Token。然后问了三个非常具体的问题,它每个问题都回答得百分之百正确。

这对学生党那可真是大利好啊。
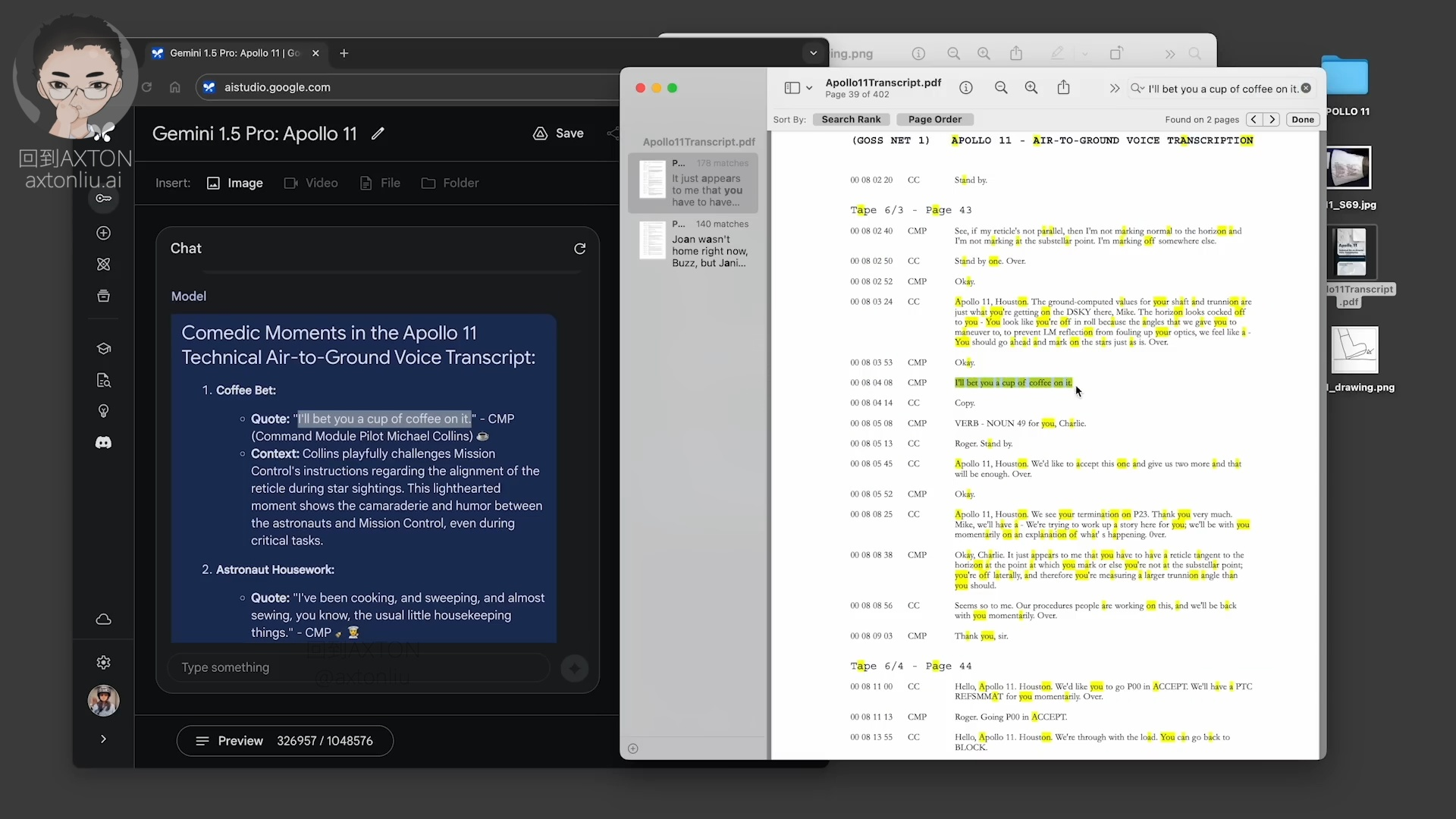
接下来,把阿波罗11号登月任务的字幕脚本,一共402页 PDF 文档交给 Gemini,然后让他”找到三个戏剧性的时刻,并列出剧本中的相关语录和对应的 Emoji”
30 秒之后,找到了三条,其中第一条是:跟我赌一杯咖啡,在原文之中确实有这句话。
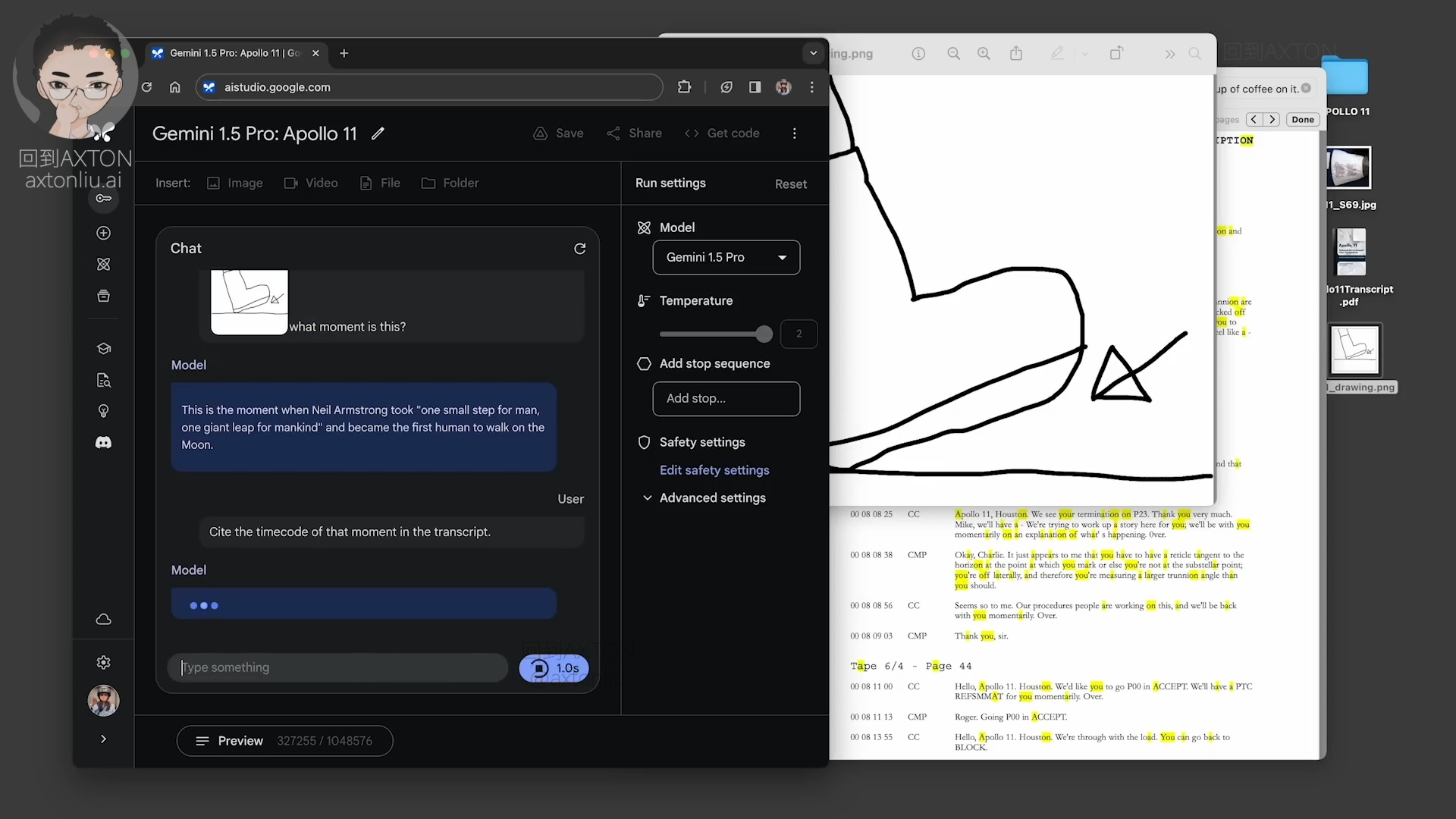
接下来测试图片提示,画了一张草图,问 Gemini,这是什么时刻?Gemini 准确地识别出了图片并查到了具体的内容,这是尼尔·阿姆斯特朗说出“这是我的一小步,却是人类的一大步”的时刻,他成为了第一个踏上月球的人类。然后接着追问:找出这句话的时间点,Gemini 准确地找出了 4 13 24 48 这个时间戳。
这只是对长文本的处理,接下来是「跨模态的理解和推理」。
跨模态的理解和推理
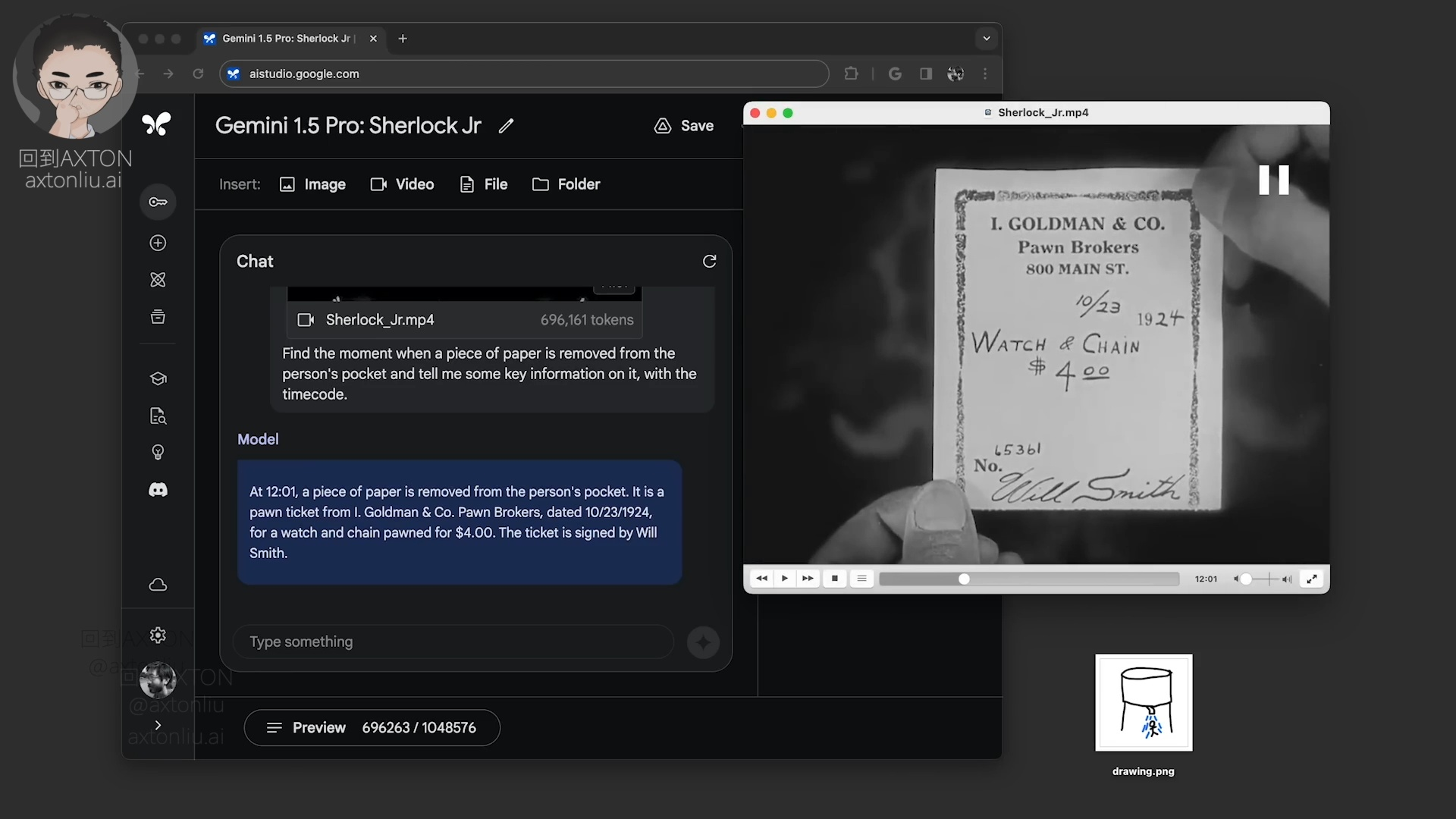
上传一段 44 分钟的影片,大约 60 万 Token,然后给了 Gemini 一个任务:找到纸张被从人物口袋中取出的时刻,并提供纸张上的关键信息以及对应的时间戳。
大约 1 分钟后,识别出来的结果是:
12:01时,一张纸从人物口袋中被取出。这是一张日期为1924年10月23日的典当行收据,典当人签名是Will Smith,典当物品为手表和表链,金额为4美元。典当行名为 I. Goldman & Co. Pawn Brokers。
在视频中定位到 12 分时我们可以看到,Gemini 查找的完全正确:
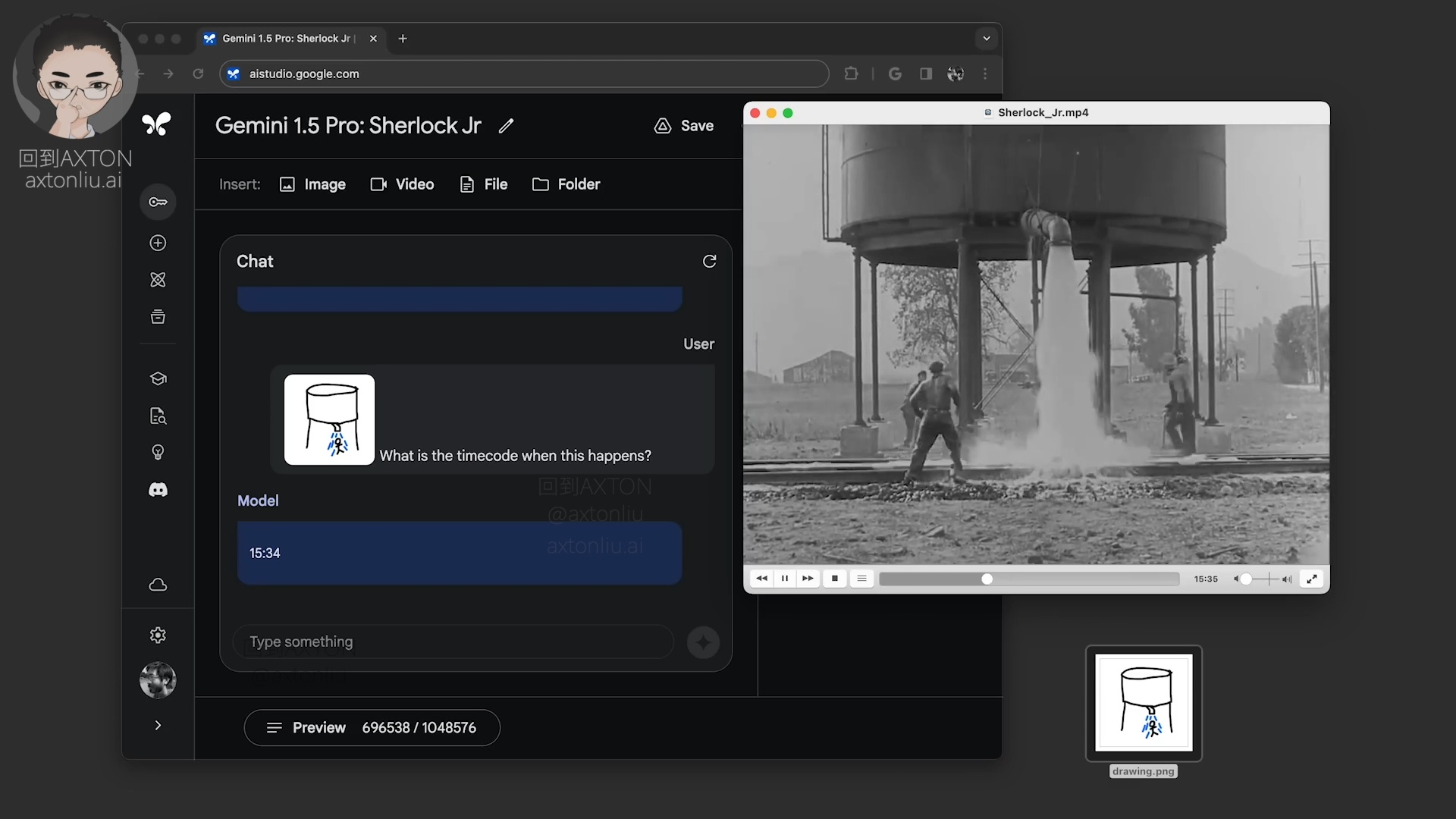
接下来跟上一次类似,又是一张灵魂画手的手绘图,问:这个事情发生的时间点是什么?
Gemini 给出答案 15:34,我们看一下,果然没错。
好,文本、视频都没问题,代码能力又如何呢?
代码能力测试
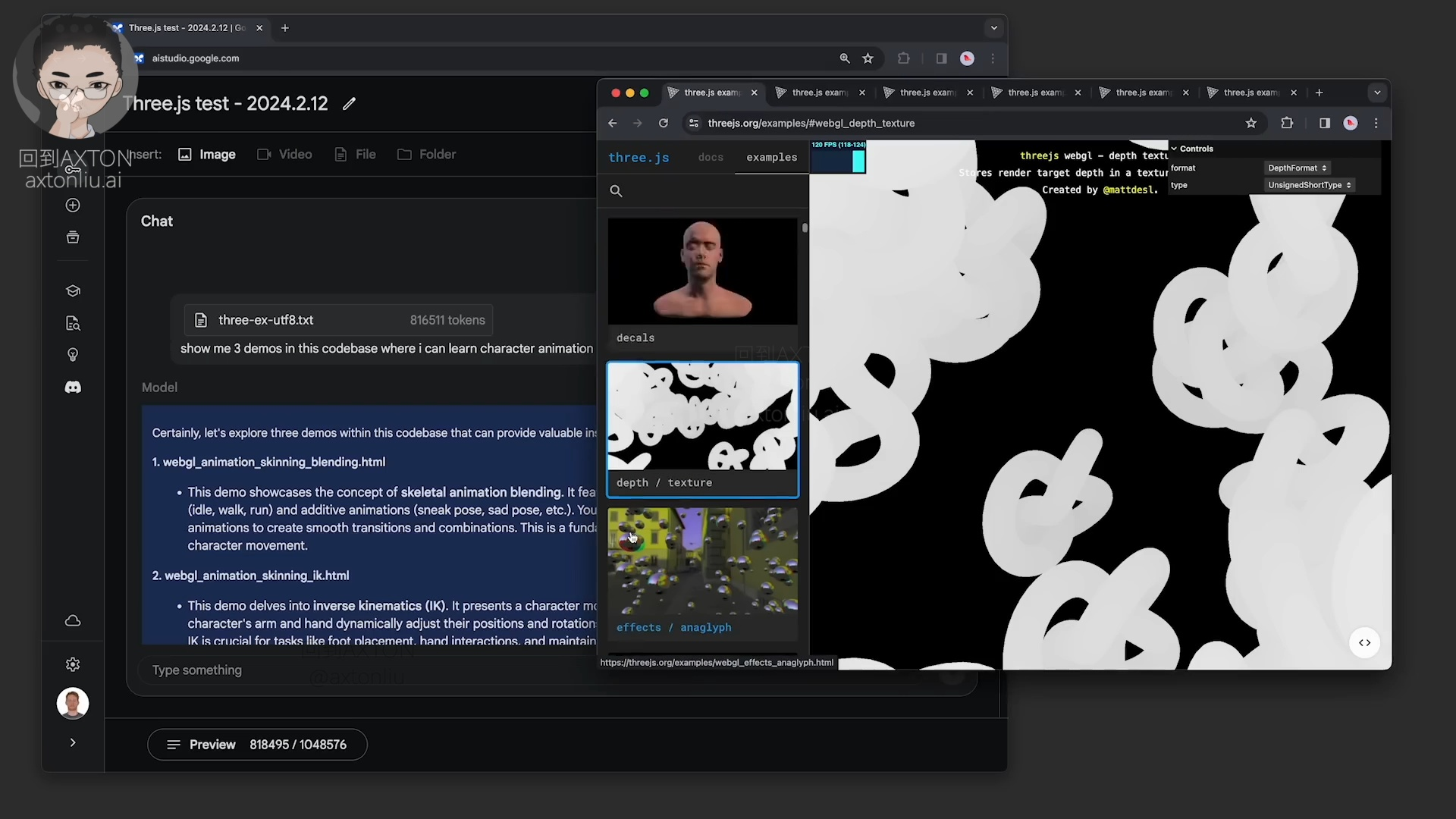
这是一个 10 万行代码,81 万 Token 的演示,Gemini 可以在代码中找到控制动画的部分代码,并且可以使用其他代码示例中的技术来编写新的代码,还能根据要求修改任何一个示例部分的代码 1:42,有了这么强大的能力,以后屎山代码就不用愁了。
但是,这些都还不够强,更强的是后面两个。
大海捞针
第一个是大海捞针测试。英文叫做NIAH, 也就是,在干草堆里找一根针 (Needle In A Haystack)。