Jina Reader API 的四种用法 | 「智图派」

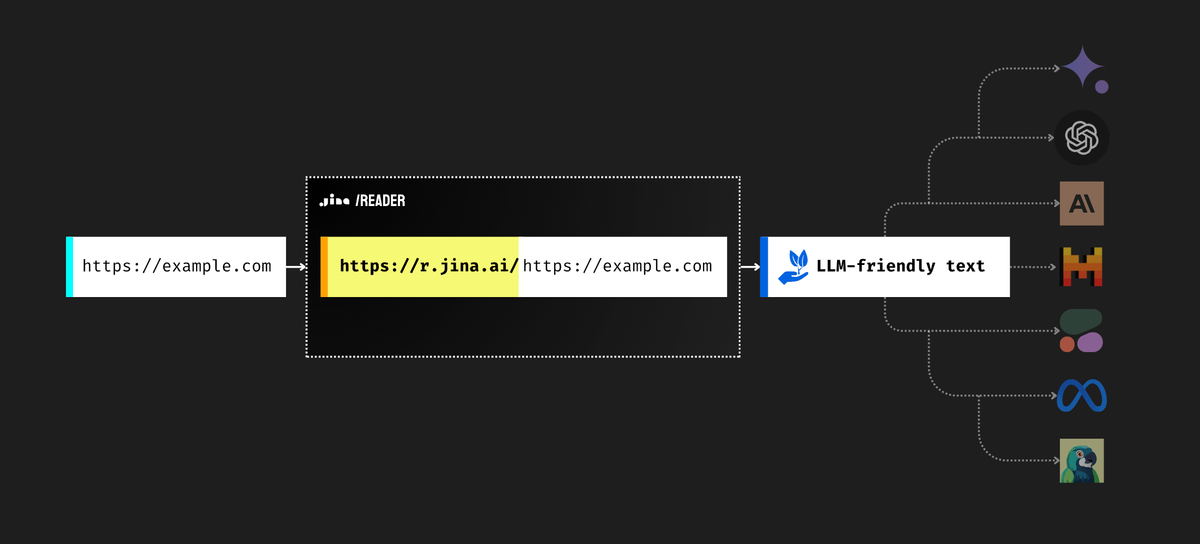
构建知识库,或者分析各种文章数据,是大家使用 AI 很重要的一个应用场景,因此我们常常会需要用到爬虫去爬取某个网站上的内容,现在,Jina 推出了一款非常简单好用的获取网页内容的工具,你只要把网址给它,它就能把网页内容整理成很适合大语言模型使用的格式,简直是构建知识库的利器。今天我就给大家介绍四种用法。分别包括在自动化工作流中使用以及在 AI 智能体中使用。
Jina Reader API 的网址是 读取器 API,你可以直接输入你需要爬取内容的网址 URL 在这边进行测试,输入之后直接点击按钮「获取内容」,就可以在右边得到结果了。
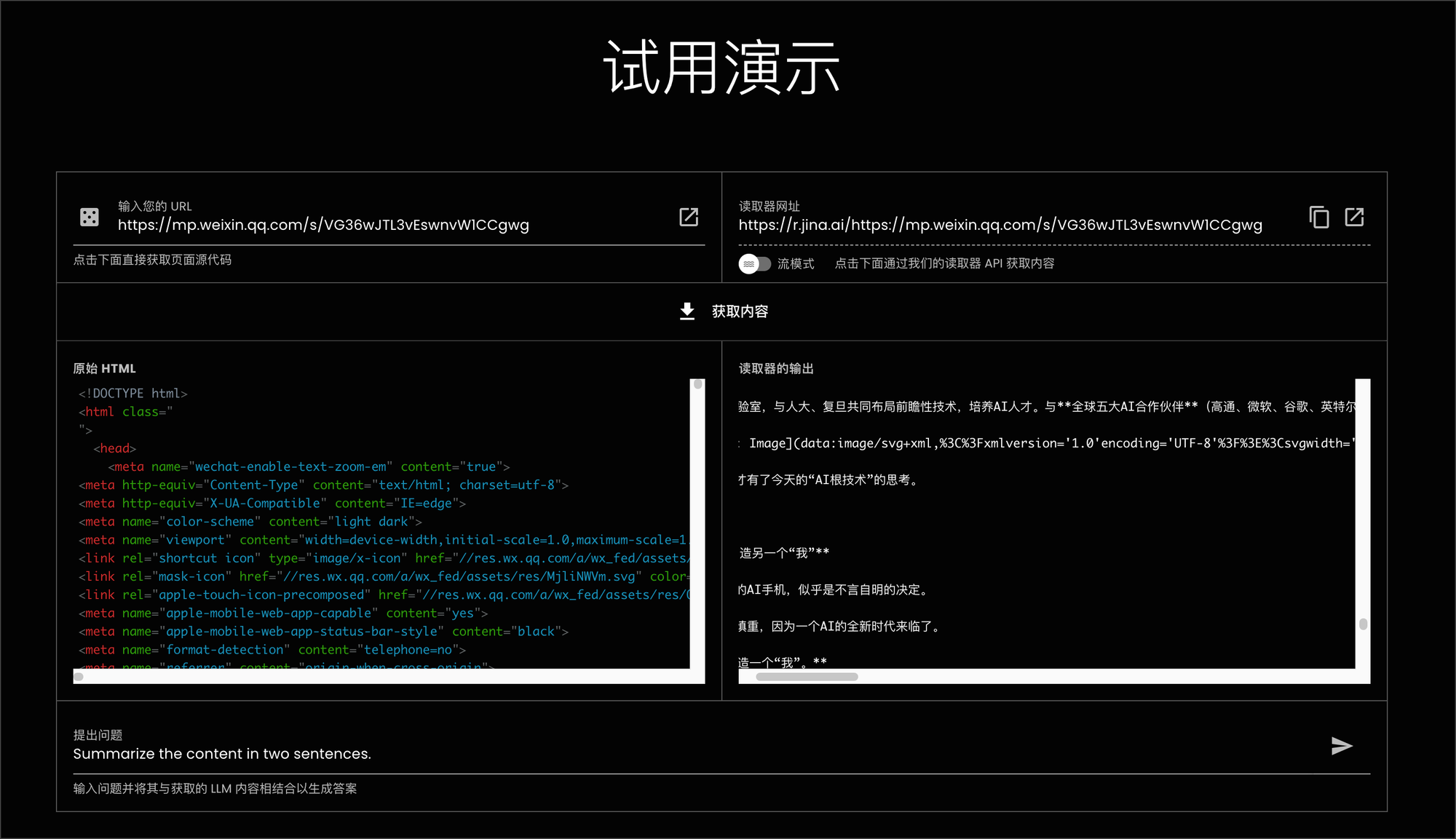
而他的用法也很简单,就是把你需要爬取内容的网页的 URL 写在 https://r.jina.ai 的后面就可以了。
什么是 Reader API
Reader 是将任何URL转换为LLM友好的输入,只需简单添加前缀 https://r.jina.ai/ 无需付费即可获得改进后的适用于智能体或 RAG 系统的输出。
这是开源项目,地址在:jina-ai/reader: Convert any URL to an LLM-friendly input with a simple prefix https://r.jina.ai/
项目中值得关注的几个参数
流模式:
当您发现标准模式提供的结果不完整时,流式模式很有用。这是因为流式模式将等待更长时间,直到页面完全呈现。使用 accept-header 切换流式模式:
curl -H "Accept: text/event-stream" https://r.jina.ai/https://example.com
使用 request headers
可以使用请求头来控制 Reader API 的行为。以下是支持的头的完整列表。
- 您可以通过
x-set-cookie头来要求 Reader API 转发 cookies 设置。 - 请注意,带有 cookies 的请求将不会被缓存。
- 您可以通过
x-respond-with头绕过readability过滤,具体如下: x-respond-with: markdown返回 markdown,不经过reability处理x-respond-with: html返回documentElement.outerHTMLx-respond-with: text返回document.body.innerTextx-respond-with: screenshot返回网页截图的 URL- 您可以通过
x-proxy-url头指定代理服务器。 - 您可以通过
x-no-cache头绕过缓存页面(生存期为 300 秒)。
JSON 模式
这仍处于非常早期的阶段,结果还不是一个真正"有用"的 JSON。它只包含三个字段 url、title 和 content。尽管如此,您可以使用 accept-header 来控制输出格式:
curl -H "Accept: application/json" https://r.jina.ai/https://en.m.wikipedia.org/wiki/Main_Page
目前发现的局限性
- 无法获取需要登录的网页
- 获取 Tweet 可能会出现问题
5 种使用方法
直接在浏览器中使用
直接在浏览器中输入 URL 就可以了,然后结果可以直接拷贝粘贴到其他地方。比如可以用下面的网址做个测试: https://www.axtonliu.ai/blog/wechat-integration-make-gpt-claude
当然,这不是 Reader API 的主要用法,因为这样还不如直接拷贝网页呢。这就是它的名字里有个 API 的原因,它最适合的用途是嵌入到你的工作流当中。接下来我就给大家讲解一下如何把这样的 API 应用到两大工作流平台 Make 和 Zapier 当中去。
Make
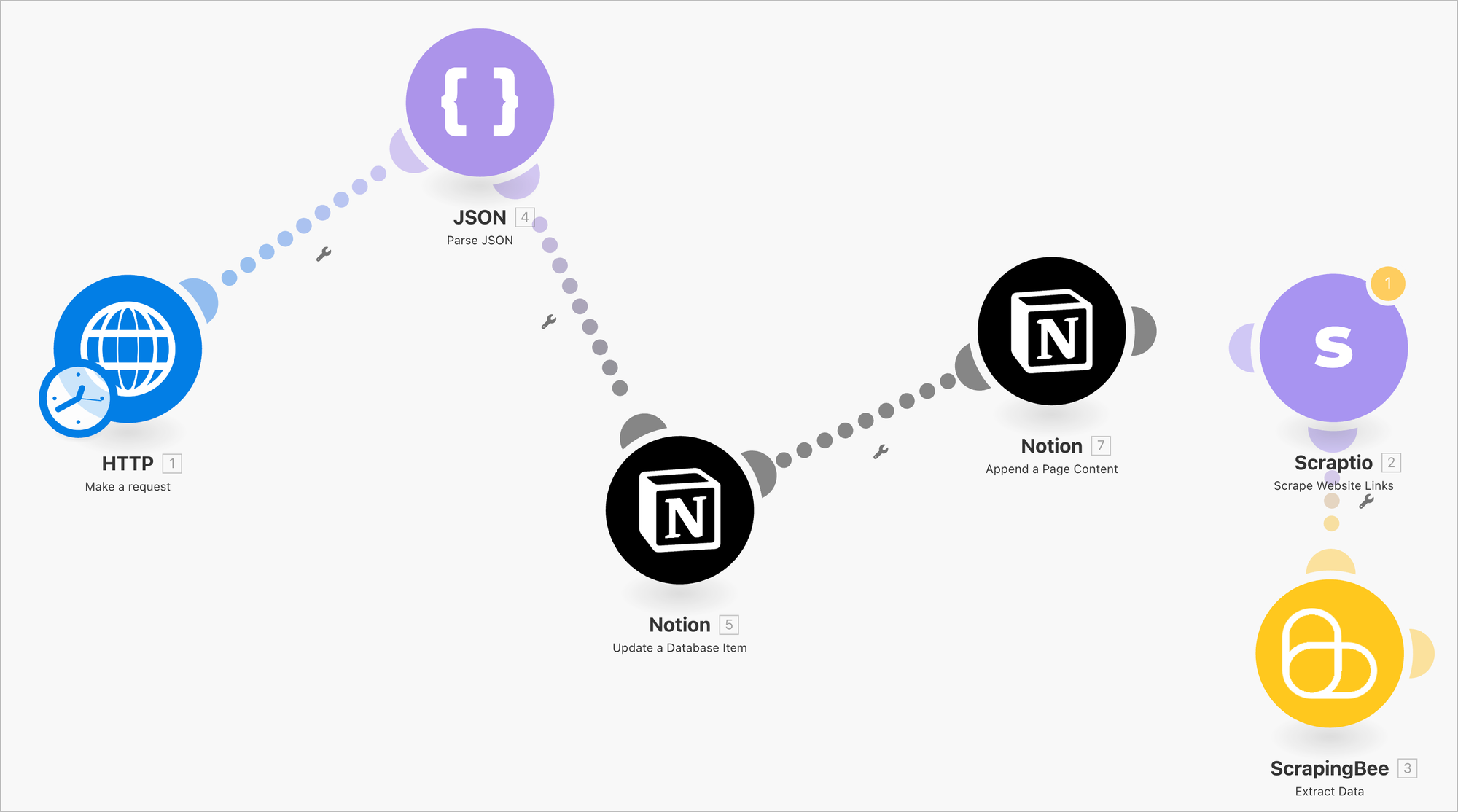
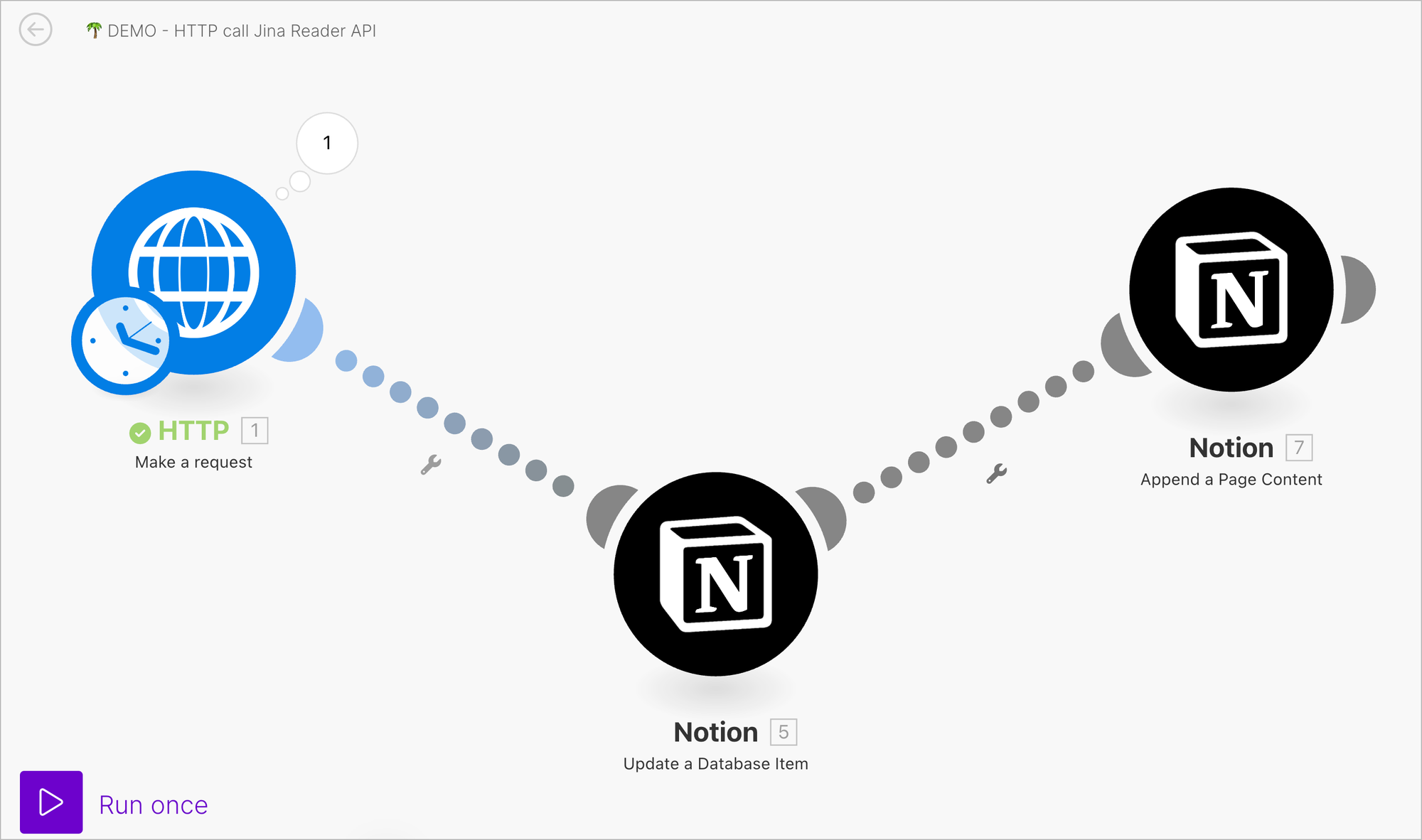
Make 调用 Reader API 很简单,而且由于 Make 能够与数千种 APP 集成,也就相当于很大程度上扩展了 Reader API 的应用范围,比如我们可以用来做一个用 Notion 爬取网页的流程。
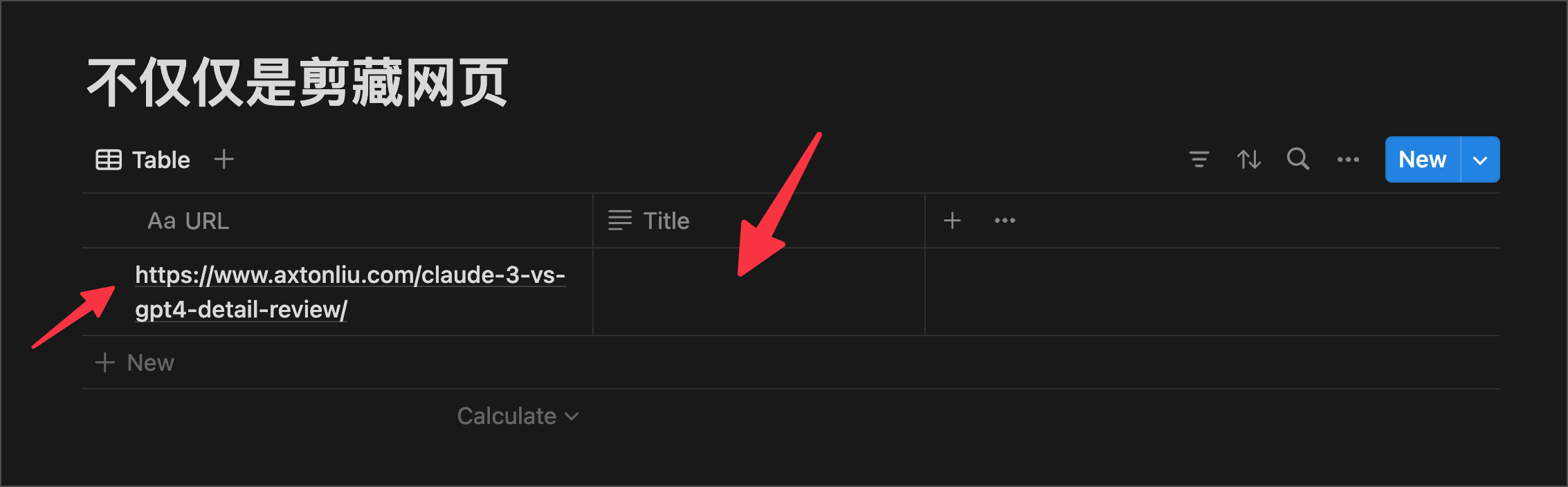
这是我们的一个测试数据库,我们可以看到,它只有一个 URL 的字段,标题 Title 是空的,也没有内容。那么,我们的 Make 流程的作用呢,就是爬取字段 URL 对应的网页内容,然后把网页内容写到 Notion 的 Page 里去。
好,我们运行一下这个 Make 的工作流:
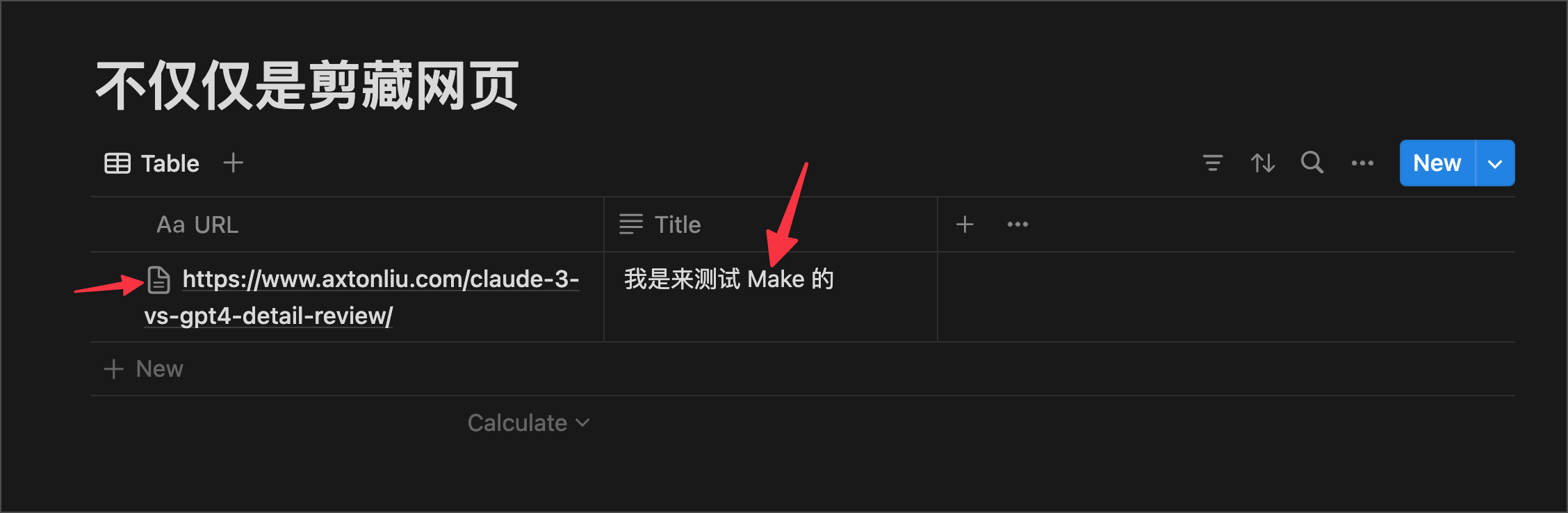
运行之后,我们可以看到页面里已经有内容了,打开看看:
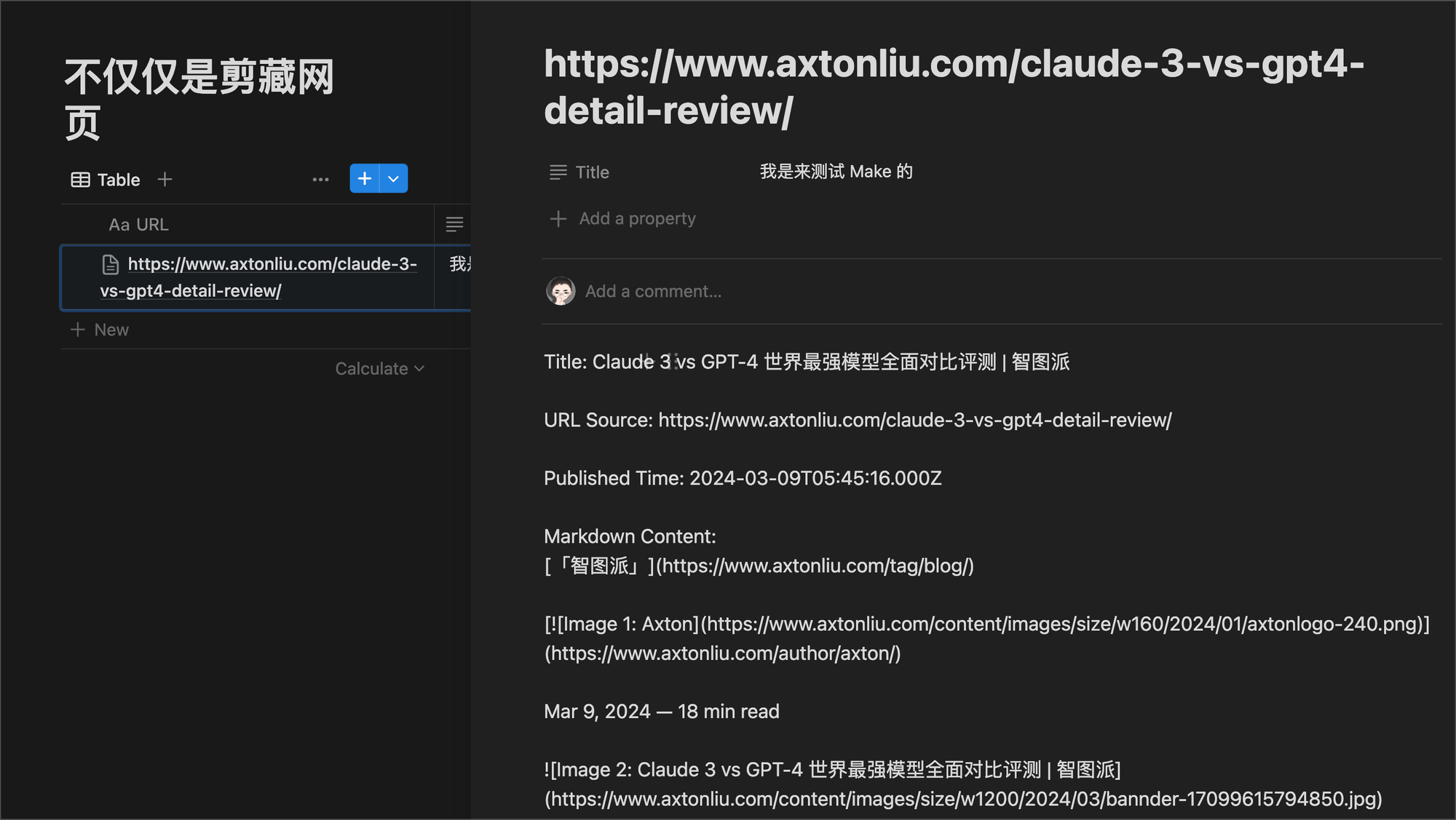
可以看到,页面的内容已经添加到 Notion 的 Page 里了。
Make 流程的详细说明:
「请忽略最右边的两个模块,那是用来测试的」